Modern systems rarely fail all at once.
They usually fail one dependency at a time.
A payment service slows down. A recommendation engine starts timing out. A third-party API begins returning errors. At first, it looks like a local issue. But if the system keeps calling that failing dependency again and again, the damage spreads.
Threads get blocked.
Retries pile up.
Resources get exhausted.
And suddenly, one weak service starts dragging down healthy ones too.
This is exactly where the circuit breaker pattern becomes important.
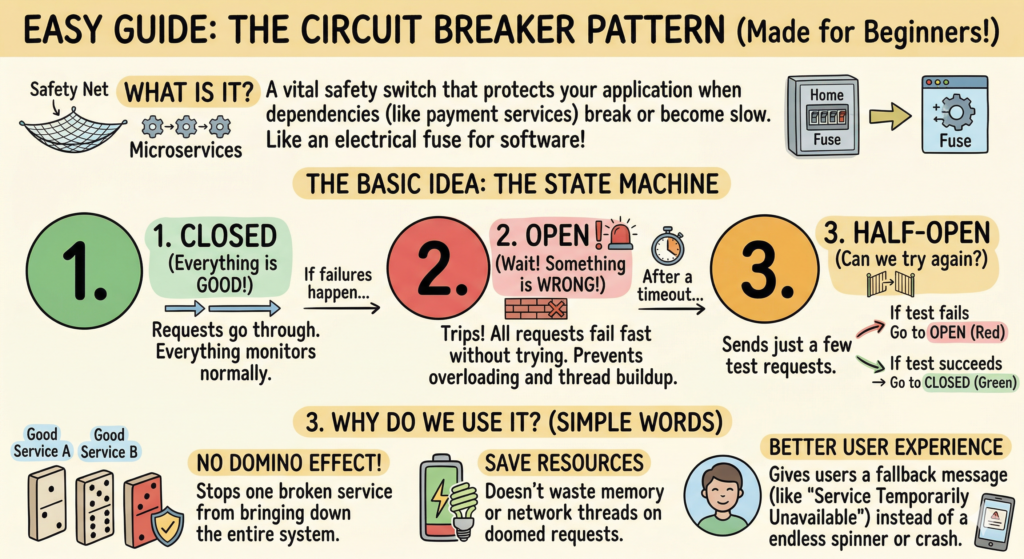
If you are trying to understand what is the circuit breaker pattern and why does it matter, the answer is simple: it is a resilience pattern that helps a system fail fast when a downstream service is unhealthy, instead of wasting resources on requests that are likely to fail anyway.
That one decision can protect the rest of the system.
What is the circuit breaker pattern?
The circuit breaker pattern is a design pattern used in distributed systems to detect repeated failures and temporarily stop calls to a failing service.
Instead of letting the application keep sending requests into a broken dependency, the circuit breaker cuts off those calls for a short period. This gives the downstream service time to recover and protects the caller from unnecessary load.
The easiest way to understand it is to think of an electrical circuit breaker in a house.
When there is an overload or a fault, the breaker trips. It stops the current from flowing to prevent damage.
Software uses the same idea.
When a service keeps failing or responding too slowly, the circuit breaker trips. It stops more requests from going through until the dependency becomes healthy again.
So in simple words, the circuit breaker pattern is a protective layer between services.
It prevents one failing part of the system from turning into a bigger outage.
Why distributed systems need the circuit breaker pattern
In monolithic systems, one process may handle most of the logic internally.
In distributed systems, things work differently.
One service depends on another. That service may depend on another one. A user request often moves through several layers before the final response is built.
Now imagine this chain:
- Service A handles the user request
- Service A calls Service B
- Service B is slow or partially down
If Service A keeps waiting on Service B, its own threads and resources stay occupied. If enough requests pile up, Service A begins to slow down too. Then other services depending on Service A may also start failing.
This is how cascading failure begins.
The circuit breaker pattern matters because it breaks that cycle early.
Instead of allowing the caller to keep suffering, it cuts off traffic to the failing dependency and lets the rest of the system stay stable.
That is why this pattern is not just a technical feature.
It is a system survival mechanism.
The real problem it solves
The circuit breaker pattern is designed to solve a very practical issue: repeated failure under dependency stress.
Without it, systems often behave badly in three ways.
1. They waste resources on calls that are already likely to fail
If a downstream service is returning timeouts or errors, sending more requests to it may achieve nothing except more failure.
2. They create thread exhaustion
Requests do not disappear just because a dependency is slow. They wait. When enough of them wait at the same time, the caller runs out of threads, memory, or connection capacity.
3. They trigger cascading failure
Once the caller starts slowing down, the effect spreads upward and sideways through the architecture. One service failure turns into a platform-level incident.
The circuit breaker pattern exists to stop that spread.
How the circuit breaker pattern works
At a high level, the circuit breaker watches the health of calls going to a dependency.
If failures cross a threshold, it changes state and begins rejecting calls immediately.
That sounds simple, but the behavior is powerful because it changes the system from slow failure to fast failure.
Fast failure is often healthier than delayed failure because it preserves resources and gives the rest of the system a chance to keep working.
The circuit breaker typically works through three states.
The three states of a circuit breaker
1. Closed state
This is the normal state.
Requests are allowed to flow to the downstream service. The circuit breaker keeps watching the outcomes of those calls, such as response failures, timeouts, or latency breaches.
As long as the failure rate stays below the threshold, everything continues normally.
So in the closed state:
- calls are allowed
- health is monitored
- no blocking happens yet
This is the healthy operating mode.
2. Open state
When the failure threshold is crossed, the breaker trips and moves to the open state.
In this state, calls to the downstream service are blocked immediately. The system does not even attempt the network call.
This is the most important protective step.
Instead of wasting time and resources on a dependency that is already failing, the application fails fast.
That means:
- no unnecessary waiting
- no repeated timeout buildup
- lower resource pressure on the caller
- reduced stress on the failing downstream service
This is the pattern doing its real job.
3. Half-open state
After a configured timeout period, the circuit breaker does not stay open forever.
It moves into a half-open state.
Here, only a small number of test requests are allowed through. These requests act like a health probe.
If those requests succeed, the breaker assumes the dependency has recovered and moves back to the closed state.
If they fail again, the breaker returns to the open state and blocks traffic for longer.
This state is important because the system needs a controlled way to check recovery without flooding the dependency too early.
A simple real-world example
Imagine an ecommerce platform during a sale.
A user places an order, and the checkout service calls a payment gateway.
Now suppose the payment gateway becomes unstable. It starts responding slowly and timing out.
Without a circuit breaker, the checkout service keeps trying to reach it. Requests pile up. User sessions hang. Thread pools fill. The checkout service becomes slow for everyone, even before the payment provider is fully unreachable.
Now add a circuit breaker.
The moment failures cross the threshold, the breaker opens. New calls to the payment service fail immediately. Instead of waiting endlessly, the application can return a fallback message like:
“Payment service is temporarily unavailable. Please try again in a few moments.”
That is not ideal, but it is far better than freezing the entire checkout flow and damaging the rest of the platform.
This is what graceful degradation looks like in practice.
Why the circuit breaker pattern matters in system design
The circuit breaker pattern matters because modern systems are built on dependencies.
And every dependency introduces risk.
If you do not control how failure behaves, your system may become fragile under pressure. A well-designed circuit breaker helps the application stay available even when some parts of the environment are unhealthy.
From a system design perspective, it matters for five major reasons.
1. It prevents cascading failures
This is the biggest reason.
The breaker isolates failure before it spreads from one service to another.
2. It protects resources
Threads, connection pools, CPU cycles, and memory are limited. Failing fast preserves them.
3. It improves resilience
The system becomes more stable during dependency outages, latency spikes, and temporary disruptions.
4. It supports graceful degradation
Instead of total failure, the system can return fallback responses, cached values, or partial functionality.
5. It improves operational visibility
A circuit breaker opening is a strong signal. It tells engineers that a dependency is unhealthy and needs attention.
What counts as a failure?
This is where system design becomes more thoughtful.
Not every bad response should trip a circuit breaker.
Teams need to define what actually counts as a failure. That may include:
- timeouts
- connection errors
- certain 5xx server responses
- latency beyond a threshold
But not every 4xx client error should be treated the same way, because those may reflect bad input rather than service instability.
This matters because poor failure classification can make the breaker too aggressive or too weak.
A badly tuned breaker can either trip too often or fail to protect the system when needed.
Important design decisions for architects
When using the circuit breaker pattern, there are a few critical design questions.
Failure threshold
How many failures should be allowed before the breaker opens?
This could be based on:
- failure count
- failure percentage
- timeout ratio
- rolling time window behavior
Open timeout duration
How long should the breaker remain open before allowing trial requests again?
Too short, and the failing service may get hammered again too quickly.
Too long, and recovery may be delayed unnecessarily.
Fallback strategy
What should the user see when the breaker is open?
Possible fallbacks include:
- cached data
- default responses
- partial UI
- “temporarily unavailable” messaging
- deferred processing
This is not just a technical decision. It is also a product decision.
Observability and alerts
Every state change should be visible.
When a breaker opens, teams should know:
- which service is affected
- when the state changed
- why it changed
- how often it is happening
Without observability, circuit breakers become silent failures instead of useful safety controls.
Circuit breaker pattern and graceful degradation
One of the most important ideas behind this pattern is graceful degradation.
Not every service needs to fail the same way.
If a “recommended products” widget is unavailable, maybe the page still loads without it.
Moreover, If a personalization service is down, maybe the platform falls back to generic content.
If a fraud-checking enrichment API is temporarily unavailable, maybe the order is queued for review instead of blocking everything instantly.
This is why the circuit breaker pattern is so valuable.
It allows the system to reduce capability without collapsing entirely.
That is a much more mature design approach than pretending every dependency will always work perfectly.
Common mistake: treating retries as enough
Some teams think retries alone will solve temporary failures.
Retries are useful, but they are not enough.
If a service is already overloaded, aggressive retries can make the problem worse. They increase traffic precisely when the failing system needs relief.
That is why retries and circuit breakers are often used together carefully.
Retries help recover from brief transient issues.
Circuit breakers stop repeated damage when the failure is more serious.
Used correctly, they complement each other.
Final thoughts
So, what is the circuit breaker pattern and why does it matter?
It is a resilience pattern that monitors failures and temporarily stops calls to an unhealthy dependency so the rest of the system can remain stable.
And it matters because distributed systems do not fail politely.
They fail in ways that spread.
Without protection, one slow or broken service can exhaust resources, trigger cascading failures, and damage user experience far beyond the original problem.
The circuit breaker pattern helps stop that chain reaction.
It makes the system fail faster, recover smarter, and degrade more gracefully.
That is why it remains one of the most important resilience patterns in modern system design.
FAQ
It is a design pattern that stops requests from repeatedly hitting a failing service, so the rest of the system stays protected.
It matters because it prevents cascading failures, saves resources, and improves resilience in distributed systems.
The three states are closed, open, and half-open.
In the open state, requests to the unhealthy dependency are blocked immediately without attempting the call.
No. It is most common in distributed systems and microservices, but it can be useful anywhere a system depends on unstable remote calls or external services.
Internal Links
what is caching and why does it matter
load balancing in system design
rate limiting in system design
what is retry logic in distributed systems
graceful degradation in system design
what is a timeout in system design
microservices communication patterns
distributed systems design basics
Pingback: What Is Auto Scaling in System Design? - Honey Srivastava